Abstract:
SQL Server 2005 Analysis Services includes a re-architecture of the Online Analytical Processing (OLAP) and Data Mining engines from SQL Server 2000. In this session we explore the semantics of the Unified Dimensional Model (or UDM) including explanations of what it is in the dimension and data structures that make calculations so flexible and query response so fast. This will be followed with a demonstration of building a cube, how multidimensional expressions (MDX) are used to query the result, and how the structure of the cube is exposed programmatically in native and managed environments. We'll end with a demonstration of building a mining model and querying the result with Data mining expressions (DMX).
Ich hatte wieder einmal die Qual der Wahl. Der letzte Slot für heute.. Puhh, bin geschafft. Hätte jetzt gleich 3 Sessions gleichzeitig besuchen können. Aber, aus aktuellem Anlass habe ich diese gewählt. ;-) Zudem erhoffe ich mir hier Infos, die uns in diesem Thema weiterbringen…. Mal schauen.
Richard ist Lead Programm Manager für Analysis Services. Er erklärt, dass er normalerweise mit DBA's spricht, Performance und Caching von Cubes ist sein "spezial" Gebiet.
Zuerst folgt eine Demo mit Excel, wo er in einer Spalte gleich "Grafiken" eingeblendet hat, wo ich eine Art "Ranking" der Zahlen sehe…
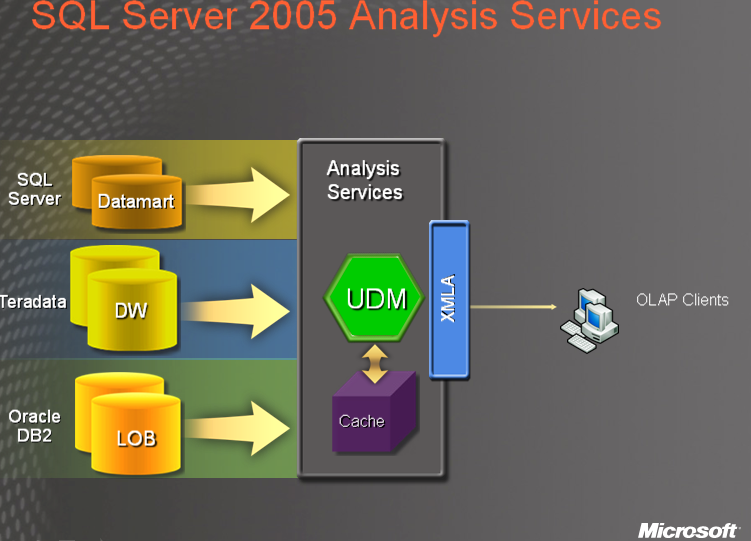
Auf die oben gezeigt Darstellung ist er leider nicht weiter eingegangen, zeigt aber eigentlich auch nur den Aufbau, wie wir Ihn schon kennen…
Er geht direkt auf die API's ein, welche Arten es für den "Zugang" gibt etc. Die folgende Grafik zeigt dies sehr schön:
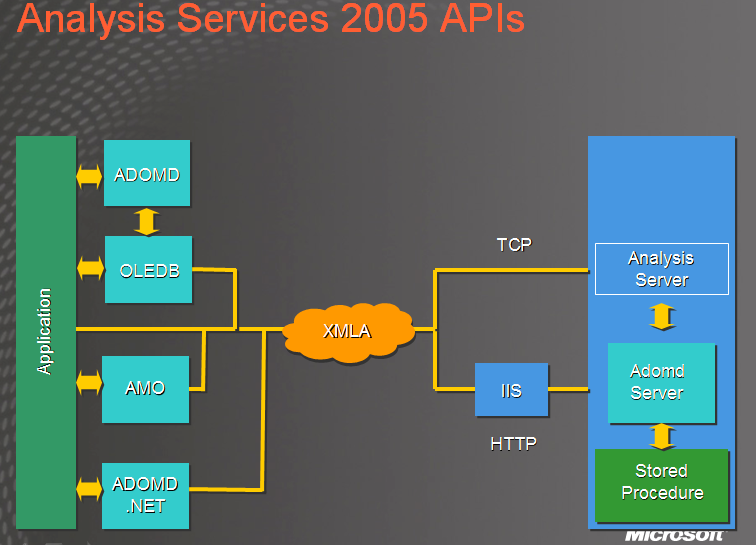
XMLA ist XML for Analysis:
• Industry standard that defines interaction between client and analytical data provider
• Specification managed by XMLA Council (www.xmla.org)
• Simple Object Access Protocol (SOAP) based XML protocol
• OLAP or data mining
• Based on OLEDB (for OLAP/data mining)
• Just two methods – Discover and Execute
Nun folgen viele Erklärungen über wie und wo ich meine Cube optimieren kann. Geht einwenig schnell ;-) Hab aber die Slides gezogen, so dass wir dies in Ruhe studieren können.
Ich bin irgendwie nicht die Zielgruppe.. Er klickt in seinem Tool herum, und ich weiss eigentlich gar nicht, was er machen will….
Jetzt kommt eine Erklärung zur Frage: Was ist eine Aggregation ?
Hier die AW:
A subtotal of partition data based on a set of attributes from each dimension
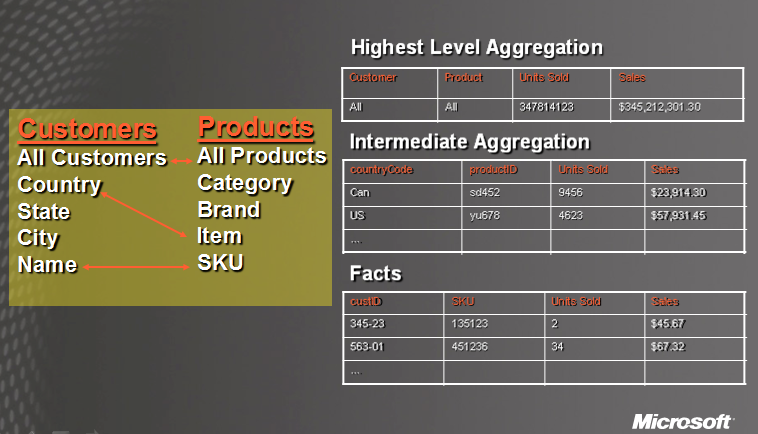
Was ich verstanden habe ist, dass eine Aggregation die Query Performance steigert. Nein im Ernst, ich glaub anhand der Grafik ist er erklärlich. Mit dem Trace Tool kann ich schauen, ob die Querys die Aggregation "treffen" oder nicht . So weiss ich auch, ob meine Aggregation "sinnvoll" ist oder nicht.
Was ist ADOMD.net ?
• Query cube schema
• GetSchemaDataSet
• Query cube data
• With MDX or SQL
• Results returned in a cellset or (flattened) rowset
• Get back a “Cellset”
• A multi-dimensional rowset
• Caution: Trace your application!
Es folgen ein paar Demos, wo er seine Cube mit Querys "quält" und zeigt, dass je nachdem er seine Cube definiert hat, sich die Perfomance massiv unterscheidet.
Leider ist mein Akku jetzt gleich leer. Es geht nun um Data mining und mdx. Ich werde noch liefern….
So, bin zufrieden von der Swiss Country Night zurück..war ein netter Abend ! Aber mehr dazu in der persönlichen Rückschau oder in einem Zwischenbericht.
Zurück zur Session….
Ok, sehr viel länger ging die Session nicht, es ging noch um Data mining (wie angedroht) und mdx. Wenn man die Kürzel zu interpretieren mag, dann weiss man auch, was wohl MDX heissen soll. Wie soll ich bloss data mining erklären.Hmm, hier ist es sehr einfach. Direkte Übersetzung ! Anbei 2 Grafiken, wo ich das besser erklären kann:
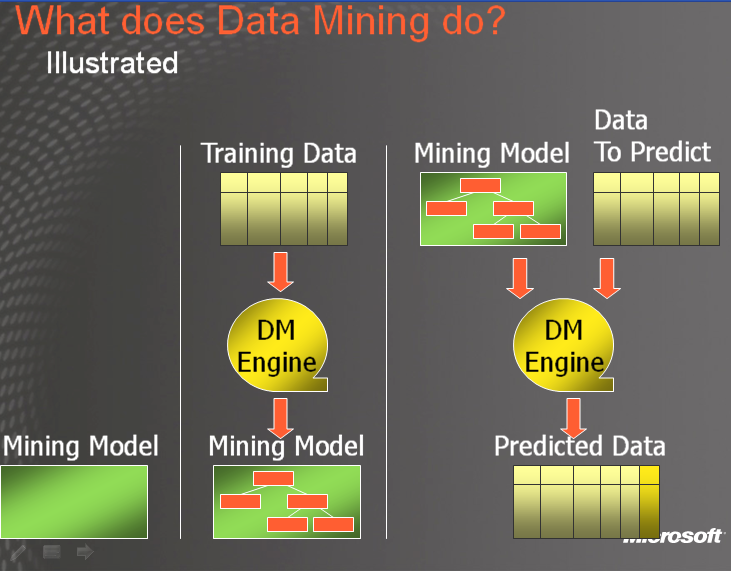
Oder anders ausgedrückt:

So, das wars ! Mehr later, there is a lot of stuff cuming !

Keine Kommentare:
Kommentar veröffentlichen